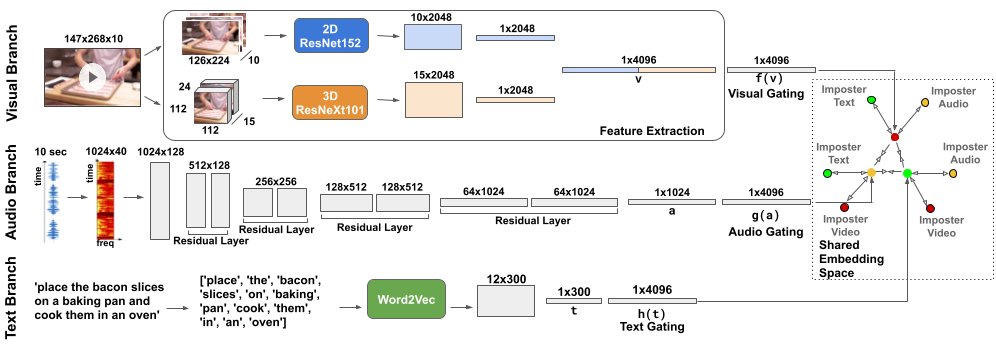
Current methods for learning visually grounded language from videos often rely on text annotation, such as human generated captions or machine generated automatic speech recognition (ASR) transcripts. In this work, we introduce the Audio-Video Language Network (AVLnet), a self-supervised network that learns a shared audio-visual embedding space directly from raw video inputs. To circumvent the need for text annotation, we learn audio-visual representations from randomly segmented video clips and their raw audio waveforms. We train AVLnet on HowTo100M, a large corpus of publicly available instructional videos, and evaluate on image retrieval and video retrieval tasks, achieving state-of-the-art performance. We perform analysis of AVLnet's learned representations, showing our model utilizes speech and natural sounds to learn audio-visual concepts. Further, we propose a tri-modal model that jointly processes raw audio, video, and text captions from videos to learn a multi-modal semantic embedding space useful for text-video retrieval.
Interspeech 2021
Interspeech 2021
Code, data, and trained models are available here.
@article{rouditchenko2020avlnet,
title={Avlnet: Learning audio-visual language representations from instructional videos},
author={Rouditchenko, Andrew and Boggust, Angie and Harwath, David and Chen, Brian and Joshi, Dhiraj and Thomas, Samuel and Audhkhasi, Kartik and Kuehne, Hilde and Panda, Rameswar and Feris, Rogerio and others},
journal={arXiv preprint arXiv:2006.09199},
year={2020}
}
@article{rouditchenko2021cascaded,
title={Cascaded Multilingual Audio-Visual Learning from Videos},
author={Rouditchenko, Andrew and Boggust, Angie and Harwath, David and Thomas, Samuel and Kuehne, Hilde and Chen, Brian and Panda, Rameswar and Feris, Rogerio and Kingsbury, Brian and Picheny, Michael and others},
journal={Proc. Interspeech 2021},
pages={3006--3010},
year={2021}
}